
Depuis 2009, Google propose un outil qui analyse les innombrables requêtes des internautes pour détecter et observer la propagation d'une épidémie (de grippe ou de dengue) dans un pays. Pour cela, la firme de Mountain View observe bien sûr certains mots-clés ("fièvre", "grippe"…) mais aussi leur distribution sur une carte, afin d'essayer de repérer les foyers mais aussi le déplacement de la maladie sur un territoire.
Combiné au big data, l'outil ouvre des perspectives pour la santé publique, via la prévention, mais aussi pour Google lui-même, dans le cadre de la médecine personnalisée. Mais il reste de gros efforts à fournir dans ce domaine, car les du suivi de la grippe par Google sont largement surinterprétés (toutes les requêtes ne sont pas entrées par des malades et tous les malades n'ont pas la grippe).
Si Google n'est pas totalement pertinent pour mesurer la grippe, Wikipédia l'est peut-être. C'est en tout cas la conclusion à laquelle arrivent John Brownstein, professeur à la faculté de médecine de l'Université Harvard et directeur du groupe de calcul épidémiologique à l'hôpital pour enfants de Boston, et David McIver, chercheur, après avoir analysé les données de recherche dans l'encyclopédie libre et gratuite.
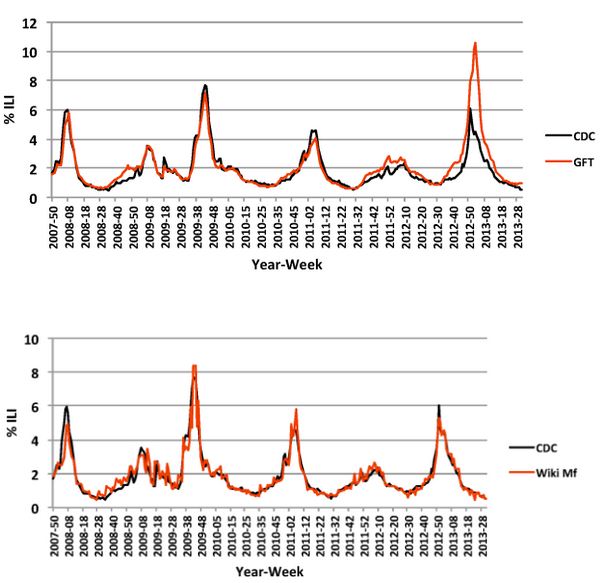
L'étude menée par les chercheurs, résumée par Quartz, montre que les informations provenant de Wikipédia sont beaucoup plus proches des données fournies par les centres pour le contrôle et la prévention des maladies (CDC) aux États-Unis. Entre 2007 et 2013, la courbe de Wikipédia se confond pratiquement avec celle des CDC, alors que celle de Google connaît quelques écarts notables (notamment en 2013).
Quelles sont les motivations derrière ces recherches ?
Comment expliquer la différence d'appréciation entre Google et Wikipédia ? Concernant Google, on peut penser que la portée de son analyse est trop vaste et qu'elle englobe à tort des requêtes qui faussent l'interprétation finale des résultats. Des internautes veulent aussi simplement se renseigner, par exemple en cherchant des actualités lors d'une épidémie de grippe. En effet, le contexte s'y prête.
Dans le cas de Wikipédia, c'est autre chose.
Bien sûr, toutes les requêtes menant vers la page "grippe" lors d'une épidémie ne sont pas entrées par des malades. Mais Wikipédia constitue la principale source unique d'information médicale pour les patients et les professionnels de la santé. Et de plus en plus d'internautes utilisent le web pour leur santé (donc Wikipédia, dans la mesure où il est très bien référencé). Cela n'est évidemment pas sans risque, car Wikipédia n'est pas un médecin.
En somme, l'écart de suivi que l'on peut constater entre l'outil de Google et celui utilisé sur Wikipédia s'expliquerait par des motivations différentes lorsque des requêtes sont passées sur le moteur de recherche et lorsque celles-ci sont entrées sur l'encyclopédie. Autrement dit, Google, outil très généraliste, est parasité par des requêtes dont les motivations sont très diverses, à la différence de Wikipédia.
+ rapide, + pratique, + exclusif
Zéro publicité, fonctions avancées de lecture, articles résumés par l'I.A, contenus exclusifs et plus encore.
Découvrez les nombreux avantages de Numerama+.
Vous avez lu 0 articles sur Numerama ce mois-ci
Tout le monde n'a pas les moyens de payer pour l'information.
C'est pourquoi nous maintenons notre journalisme ouvert à tous.
Mais si vous le pouvez,
voici trois bonnes raisons de soutenir notre travail :
- 1 Numerama+ contribue à offrir une expérience gratuite à tous les lecteurs de Numerama.
- 2 Vous profiterez d'une lecture sans publicité, de nombreuses fonctions avancées de lecture et des contenus exclusifs.
- 3 Aider Numerama dans sa mission : comprendre le présent pour anticiper l'avenir.
Si vous croyez en un web gratuit et à une information de qualité accessible au plus grand nombre, rejoignez Numerama+.

Toute l'actu tech en un clin d'œil
Ajoutez Numerama à votre écran d'accueil et restez connectés au futur !
Tous nos articles sont aussi sur notre profil Google : suivez-nous pour ne rien manquer !