Mise à jour : l'indexation est toujours permise hors du sous-domaine www, via le fichier http://twitter.com/robots.txt. Soit c'est un oubli de la part de Twitter, soit le réseau social privilégie le référencement hors www.

Ceux qui voudront indexer Twitter pour réaliser leur propre moteur de recherche ou pour conserver des archives automatisées devront obligatoirement signer un contrat avec Twitter pour avoir accès à son API, comme l'a fait Google. Le réseau social a en effet modifié son fichier robots.txt qui fixe les règles que les robots d'indexation sont censées suivre, et elles sont désormais simplissimes. Plus aucun robot n'est autorisé à crawler dans les pages de Twitter, que ce soit pour accéder aux messages publiés par les utilisateurs, ou même pour indexer des pages relativement statiques comme le règlement du site, les pages d'aide, le blog officiel, les documentations des API, etc.
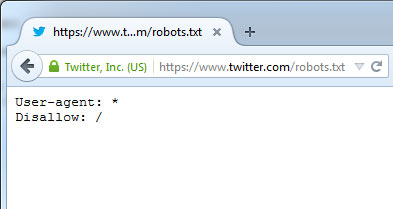
Aucune loi n'impose de respecter les règles décrites dans le fichier robots.txt, mais il s'agit d'une convention partagée par l'ensemble des grands moteurs de recherche, et globalement suivie par la plupart des agents d'indexation. Par ailleurs le fichier sitemap.xml, qui donnait aux moteurs de recherche et autres robots d'indexation une cartographie du site pour faciliter leurs travaux de référencement, est désormais vide.
Nous reproduisons ci-dessous le robots.txt tel qu'il apparaissait jusqu'à cette mise à jour radicale :
#Google Search Engine Robot User-agent: Googlebot Allow: /?_escaped_fragment_ Allow: /*?lang= Allow: /hashtag/*?src= Allow: /search?q=%23 Disallow: /search/realtime Disallow: /search/users Disallow: /search/*/grid Disallow: /*? Disallow: /*/followers Disallow: /*/following Disallow: /account/not_my_account #Yahoo! Search Engine Robot User-Agent: Slurp Allow: /?_escaped_fragment_ Allow: /*?lang= Allow: /hashtag/*?src= Allow: /search?q=%23 Disallow: /search/realtime Disallow: /search/users Disallow: /search/*/grid Disallow: /*? Disallow: /*/followers Disallow: /*/following Disallow: /account/not_my_account #Yandex Search Engine Robot User-agent: Yandex Allow: /?_escaped_fragment_ Allow: /*?lang= Allow: /hashtag/*?src= Allow: /search?q=%23 Disallow: /search/realtime Disallow: /search/users Disallow: /search/*/grid Disallow: /*? Disallow: /*/followers Disallow: /*/following Disallow: /account/not_my_account #Microsoft Search Engine Robot User-Agent: msnbot Allow: /?_escaped_fragment_ Allow: /*?lang= Allow: /hashtag/*?src= Allow: /search?q=%23 Disallow: /search/realtime Disallow: /search/users Disallow: /search/*/grid Disallow: /*? Disallow: /*/followers Disallow: /*/following Disallow: /account/not_my_account # Every bot that might possibly read and respect this file. User-agent: * Allow: /*?lang= Allow: /hashtag/*?src= Allow: /search?q=%23 Disallow: /search/realtime Disallow: /search/users Disallow: /search/*/grid Disallow: /*? Disallow: /*/followers Disallow: /*/following Disallow: /account/not_my_account Disallow: /oauth Disallow: /1/oauth Disallow: /i/streams Disallow: /i/hello # Wait 1 second between successive requests. See ONBOARD-2698 for details. Crawl-delay: 1 # Independent of user agent. Links in the sitemap are full URLs using https:// and need to match # the protocol of the sitemap. Sitemap: https://twitter.com/sitemap.xml
+ rapide, + pratique, + exclusif
Zéro publicité, fonctions avancées de lecture, articles résumés par l'I.A, contenus exclusifs et plus encore.
Découvrez les nombreux avantages de Numerama+.
Vous avez lu 0 articles sur Numerama ce mois-ci
Tout le monde n'a pas les moyens de payer pour l'information.
C'est pourquoi nous maintenons notre journalisme ouvert à tous.
Mais si vous le pouvez,
voici trois bonnes raisons de soutenir notre travail :
- 1 Numerama+ contribue à offrir une expérience gratuite à tous les lecteurs de Numerama.
- 2 Vous profiterez d'une lecture sans publicité, de nombreuses fonctions avancées de lecture et des contenus exclusifs.
- 3 Aider Numerama dans sa mission : comprendre le présent pour anticiper l'avenir.
Si vous croyez en un web gratuit et à une information de qualité accessible au plus grand nombre, rejoignez Numerama+.

Toute l'actu tech en un clin d'œil
Ajoutez Numerama à votre écran d'accueil et restez connectés au futur !
Pour ne rien manquer de l’actualité, suivez Numerama sur Google !