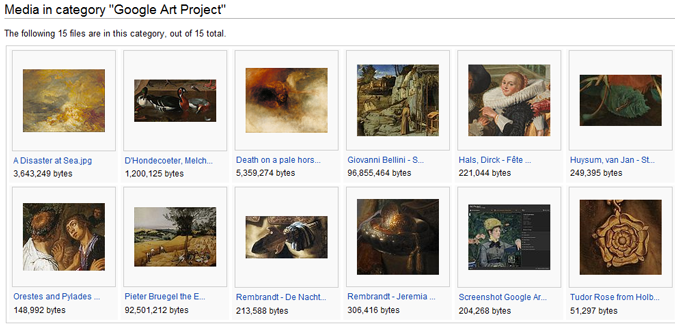
Ce mois-ci Google a révélé son intiative Google Art Project, qui a soulevé l’admiration partout dans le monde. La firme de Mountain View donne accès à la visite virtuelle de 17 musées, et permet de scruter plus de 1000 tableaux photographiés en haute résolution. Mais il est un aspect qui a été fortement négligé, y compris par Numerama ; celui de l’appropriation d’œuvres du domaine public. Un problème soulevé sur son blog par Adrienne Alix, la présidente de Wikimédia France, et détaillé dans un excellent article d’Ecrans.
Plutôt que d’ouvrir son catalogue d’œuvres numérisées, Google a créé une interface entièrement en Flash qui ne permet pas le téléchargement des toiles. Ceux qui souhaitent les consulter doivent obligatoirement passer par l’interface propriétaire et fermée de Google, sans possibilité de les archiver, par exemple pour une utilisation éducative. « L’imagerie haute résolution des œuvres d’art appartient aux musées, et ces images sont protégées par les lois sur le droit d’auteur et le copyright« , indiquent les conditions d’utilisation de Google Art Project, quand bien même la plupart des œuvres sont passées depuis longtemps dans le domaine public. La firme américaine prétend que la numérisation est en elle-même une œuvre protégée par le droit d’auteur, ce qui est loin d’être garanti en cas de conflit devant les tribunaux.
Adrienne Alix craint que les musées, qui ont peur de perdre le contrôle des œuvres de leur catalogue, ne préfèrent s’en remettre à une solution très étroitement contrôlée comme celle de Google, plutôt que de faire don des imageries haute résolution à un fonds libre comme Wikimedia Commons.
Pour leur forcer la main, un passionné nommé Derrick Coetzee a cependant commencé à reconstituer manuellement les images de Google, avec une patience folle. « Pour chaque tableau reconstitué, » Dcoetzee » a zoomé au maximum sur l’image de Google pour avoir un détail en très gros plan, pris une capture d’écran, puis déplacé sa zone de zoom de quelques centimètres sur le tableau, prix une nouvelle capture d’écran… et ainsi de suite, sans doute des milliers de fois, jusqu’à pouvoir reconstituer le puzzle à partir des minuscules pièces péniblement récupérées« , rapporte Ecrans. Le résultat se présente sous la forme d’une quinzaine d’œuvres déjà reprises sur Wikimedia Commons, avec des fichiers qui pèsent jusqu’à 95 Mo. La Fondation Wikimedia semble prête à entamer un bras de fer avec Google si le géant décidait de s’attaquer à Wikimedia, ce qu’il évitera probablement pour s’épargner une mauvaise campagne de presse.
+ rapide, + pratique, + exclusif
Zéro publicité, fonctions avancées de lecture, articles résumés par l'I.A, contenus exclusifs et plus encore.
Découvrez les nombreux avantages de Numerama+.
Vous avez lu 0 articles sur Numerama ce mois-ci
Tout le monde n'a pas les moyens de payer pour l'information.
C'est pourquoi nous maintenons notre journalisme ouvert à tous.
Mais si vous le pouvez,
voici trois bonnes raisons de soutenir notre travail :
- 1 Numerama+ contribue à offrir une expérience gratuite à tous les lecteurs de Numerama.
- 2 Vous profiterez d'une lecture sans publicité, de nombreuses fonctions avancées de lecture et des contenus exclusifs.
- 3 Aider Numerama dans sa mission : comprendre le présent pour anticiper l'avenir.
Si vous croyez en un web gratuit et à une information de qualité accessible au plus grand nombre, rejoignez Numerama+.

Toute l'actu tech en un clin d'œil
Ajoutez Numerama à votre écran d'accueil et restez connectés au futur !
Anticipez le futur en vous inscrivant gratuitement à ToujoursPlus, la newsletter tech de référence.