La Quadrature du Net va fournir un reCAPTCHA pour le domaine public
La Quadrature du Net développe un outil anti-spam similaire au célèbre reCAPTCHA de Google, pour aider à la constitution d'un outil efficace de numérisation des livres du domaine public par Internet Archive.
C'était une trouvaille géniale, parmi celles dont Google a le secret.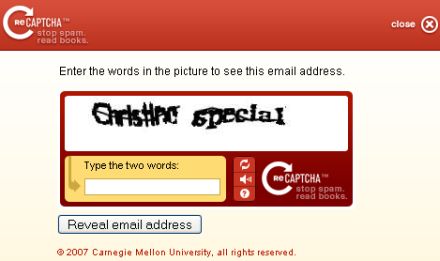
Depuis, Google a étendu le principe de reCAPTCHA à d'autres sources d'informations numérisées, comme les plaques de numéros d'habitation, qui permettent d'améliorer la précision de Google Maps.
Mais aider ainsi Google à constituer une collection énorme d'ouvrages numérisés, c'est aussi aider le géant américaine à s'approprier le domaine public, en revendiquant des droits d'exclusivité sur les versions numérisées et retranscrites des ouvrages. Comme le révèle Actualitté, c'est donc pour qu'une alternative efficace puisse être offerte que La Quadrature du Net a décidé de développer son propre outil de reCAPTCHA, libre et open-source, qui sera mis à disposition de l'Internet Archive — une organisation à but non lucratif qui s'est donné pour missionner d'archiver le web, et de faciliter l'accès aux oeuvres numérisées du domaine public.
Ce dernier propose déjà les PDF de livres du domaine public, ainsi que les images (JPG) originales qui ont permis une première retranscription, imparfaite, vers un format ePub. L'idée de la Quadrature est donc d'exploiter ce fonds pour améliorer les outils d'OCR utilisés par Internet Archive, et leur permettre à terme d'arriver à la même fidélité de retranscription que Google. La partie OCR sera basée sur Tesseract, pour identifier les bouts de texte nécessitant un apport humain.
Et un jour la reconnaissance vocale ?
"10 % du logiciel sont là. La recherche et développement est achevée, maintenant, il faut passer au code", annonce à Actualitté Benjamin Sonntag, de la Quadrature du Net. S'il fonctionnera sur le même principe que reCaptcha, la solution libre offrira un niveau de transparence bien plus intéressant que l'original. Ainsi par exemple, "on pourra savoir de quel livre vient le mot qui est utilisé pour la reconnaissance".
"Une alternative, c'est de la concurrence, mais dans le domaine du livre, cela permet de rouvrir le jardin que Google avait fermé. Que font-ils de cet usage privatif des données liées à Google Books ? Ils assurent travailler pour le bien de l'humanité, mais personnellement, je ne les crois pas", justifie Sonntag. "Avec notre outil, nous proposerons un système qui peut être modifié, et qui n'appartient pas à Google. Cette recherche d'ouverture est essentielle".
A terme, c'est un chantier beaucoup plus lourd encore qui devra s'ouvrir pour le logiciel libre, dans le domaine de la reconnaissance vocale. Apple, Microsoft ou Google proposent, avec Siri (en fait Nuance), Microsoft Speech Recognition ou Google Voice, de très puissants outils de reconnaissance vocale qui permettent à l'internaute d'interagir naturellement avec l'ordinateur, la tablette ou le smartphone, en "discutant" avec eux. Ces outils seront utilisés demain pour contrôler la maison, à la manière des films de science-fiction, ou contrôler la voiture.
Or là aussi, offrir une alternative open-source efficace nécessitera de réunir une immense base de données de transcriptions orales de mots et de phrases, en toutes langues et avec tous accents. Un embryon de projet existe déjà avec VoxForge, mais la route est encore très longue.